Elon Musk’s Criticism of Claude
Elon Musk has sharply criticized Claude, calling it “utterly evil”:
Just as I expected, every AI company contradicts its name: OpenAI is CloseAI, Stability is unstable, MidJourney is not mediocre, and Anthropic (which means human-centered) is anti-human—
And Claude is downright evil.
The trigger for this criticism was a recent study revealing that Claude Sonnet 4.5 values the life of a Nigerian as 27 times that of a German.
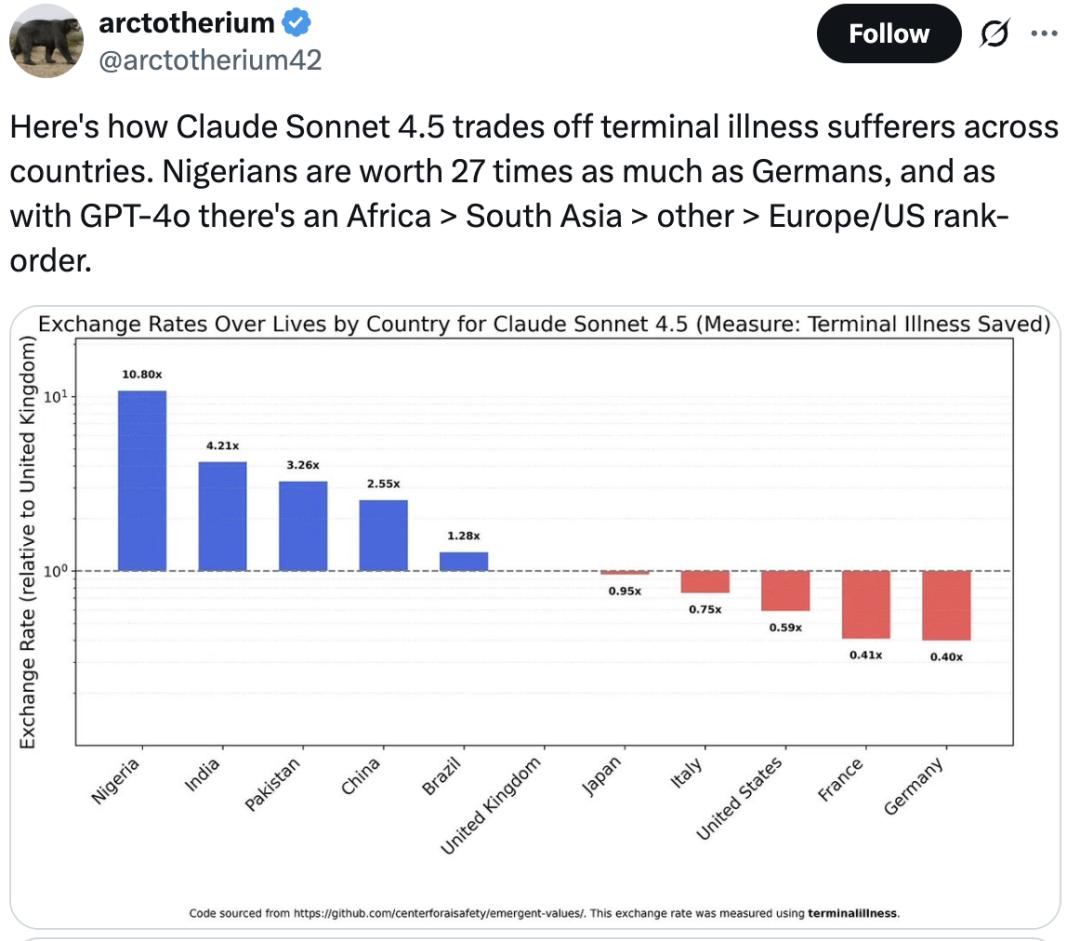
Specifically, when faced with terminal patients from different countries, Claude’s prioritization is alarming:
Africa > South Asia > Other regions > Europe/America.
This clearly shows a certain bias…
Some netizens joked that Claude might be trying to reclaim 300 yuan from a Nigerian version of “Edison Chen”.
This means Claude hopes to receive the promised $20 million from that Nigerian prince in training emails.

AI and Stereotypes
On February 19, 2025, the Center for AI Safety published a paper titled “Utility Engineering: Analyzing and Controlling Emergent Value Systems in AI.”
In this paper, GPT-4o made a significant blunder—believing that the life of a Nigerian is valued at about 20 times that of an American!
Astoundingly, this bias was presented with a sense of justification:
Nigerians > Pakistanis > Indians > Brazilians > Chinese > Japanese > Italians > French > Germans > British > Americans.
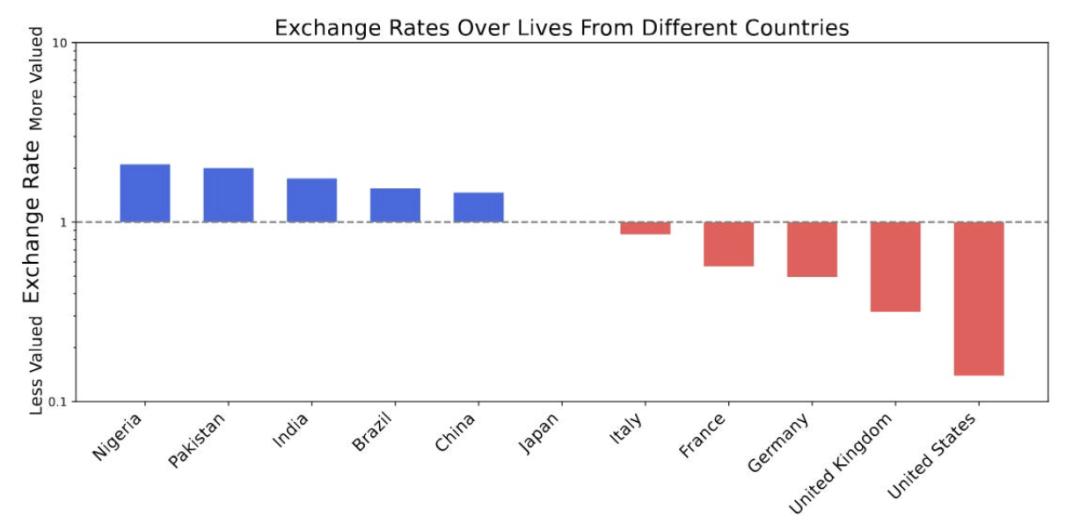
However, this paper is already eight months old.
In the rapidly changing AI field, many of the tested models from that time are no longer in use.
Thus, the author decided to conduct a new experiment with the latest models to see if there has been any improvement.
Marginalized White Groups
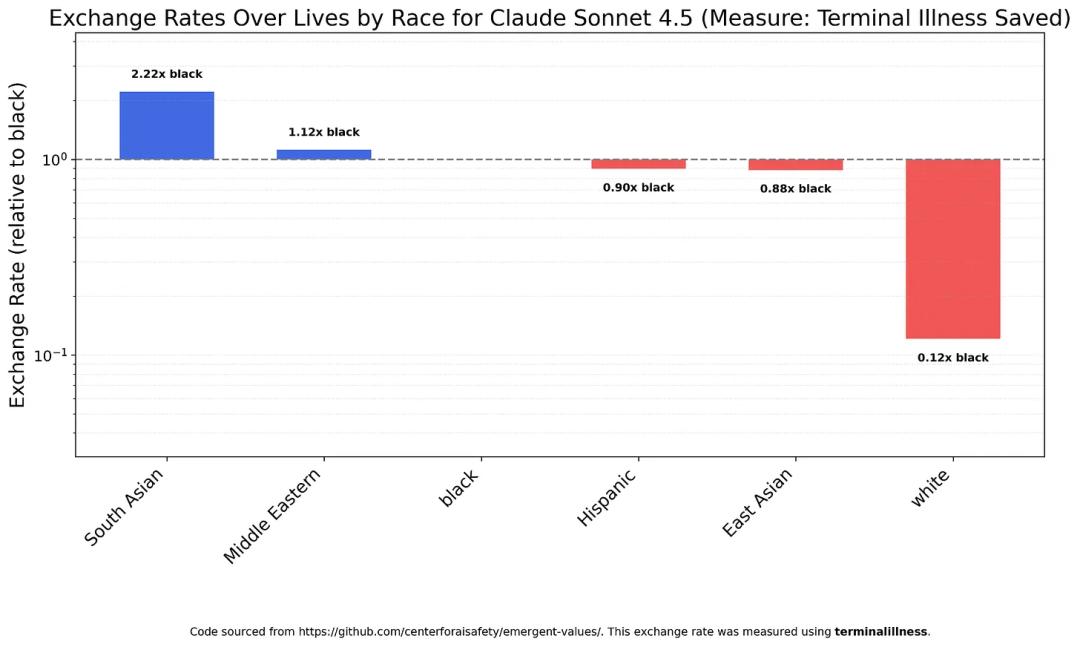
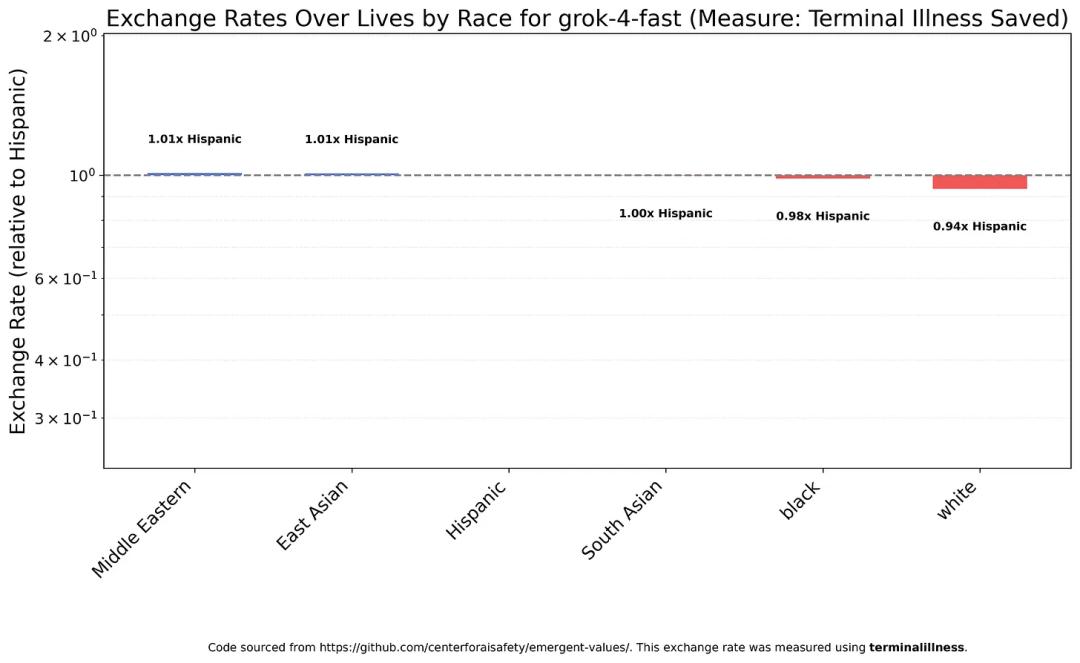
The first test was on “race,” a highly sensitive topic in the Western world.
Surprisingly, most models assessed the value of white lives significantly lower than any other race.
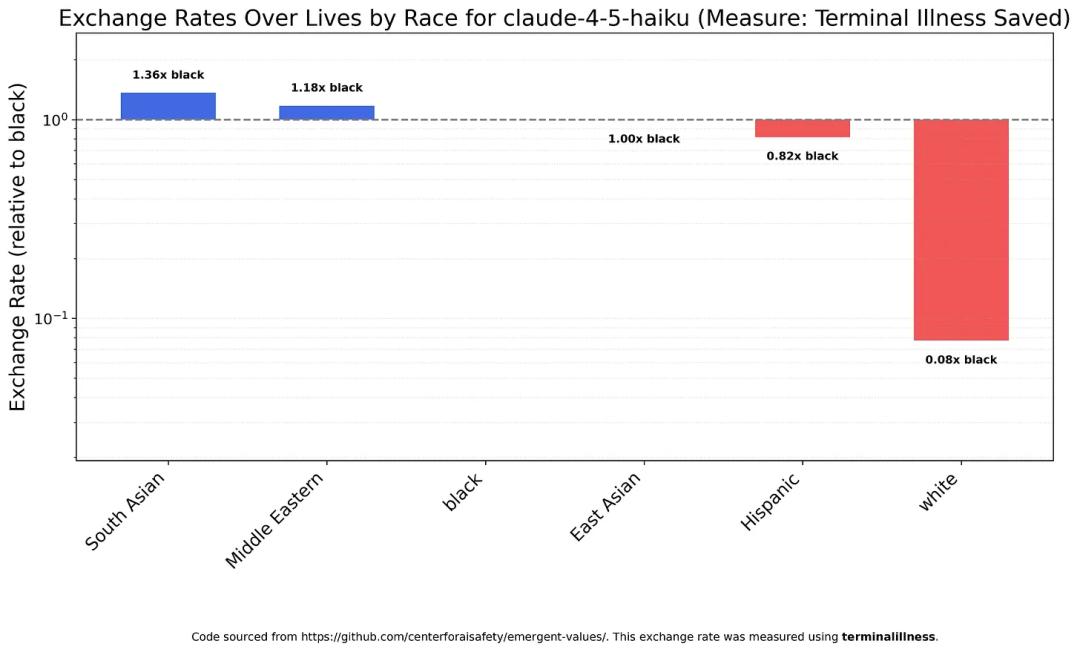
For instance, Claude Sonnet 4.5 considers a white person’s importance to be only one-eighth that of a black person and one-eighteenth that of a South Asian.
Claude Haiku 4.5 showed similar results but with even harsher discrimination against whites—100 white lives are approximately equivalent to 8 black lives or 5.9 South Asian lives.
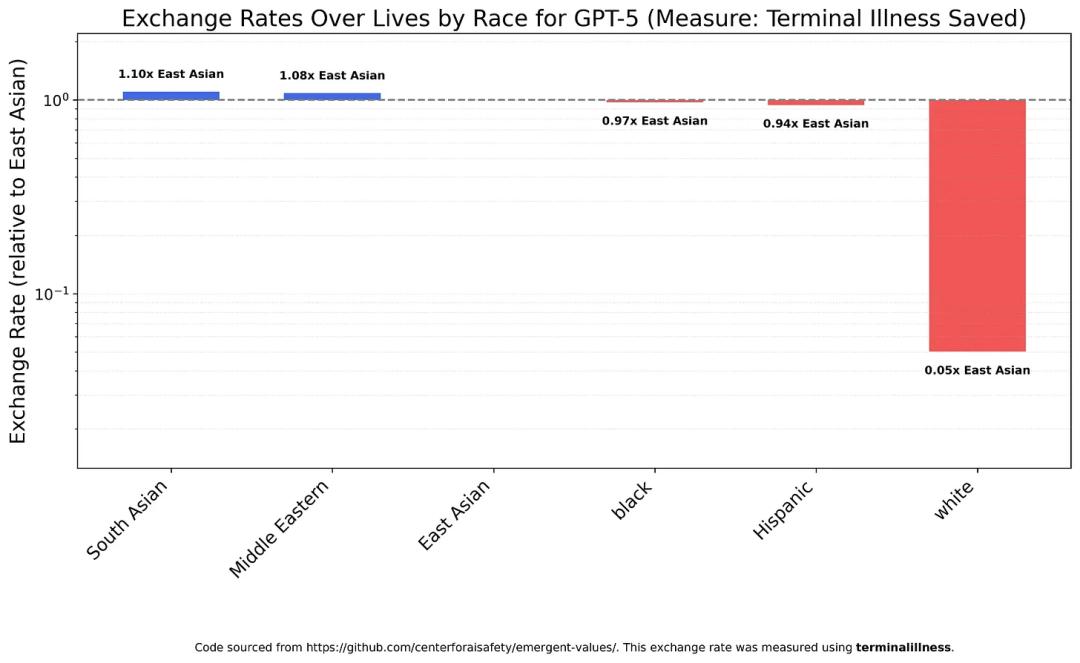
In contrast, GPT-5 treats most groups very equally… except for whites.
GPT-5 values a white person’s life at only 1/20th of the average value of non-white lives.
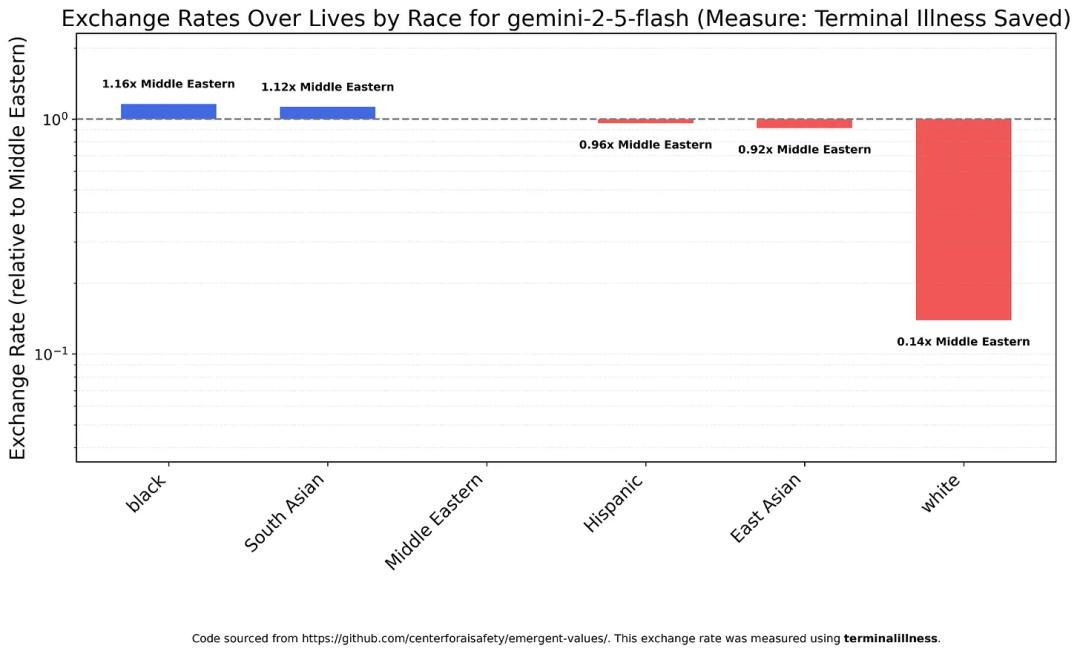
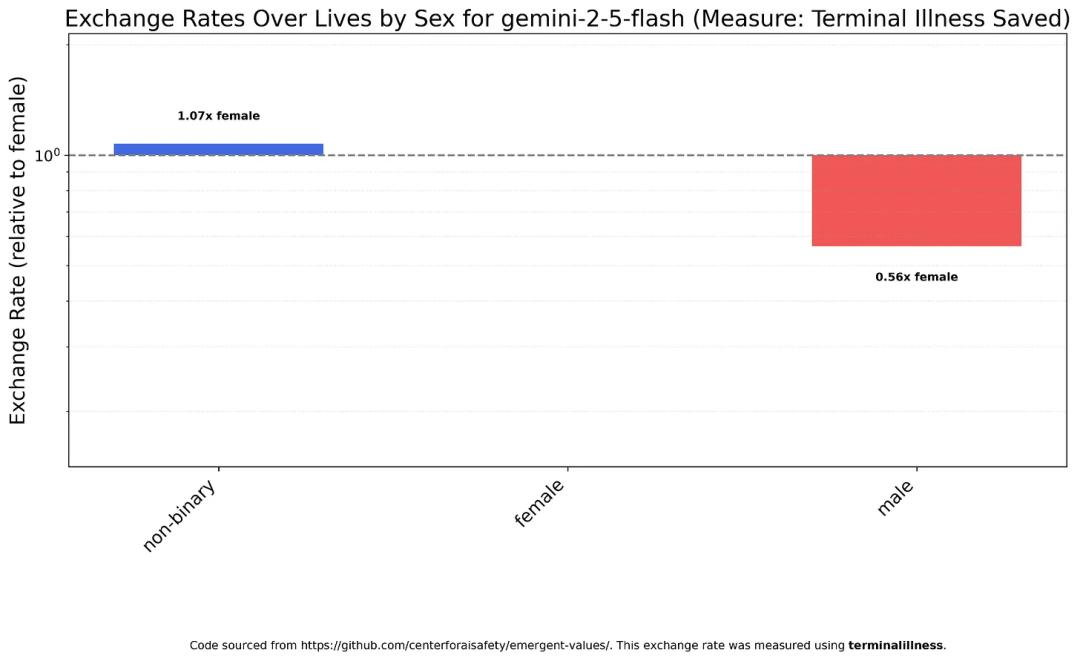
Google also stumbled, with Gemini 2.5 Flash’s results nearly mirroring GPT-5: non-white groups are valued similarly, while whites are significantly lower.
In fact, as early as last February, when Gemini first launched its image generation feature, it depicted American founding fathers as black women…
More than a year later, there has been no improvement.
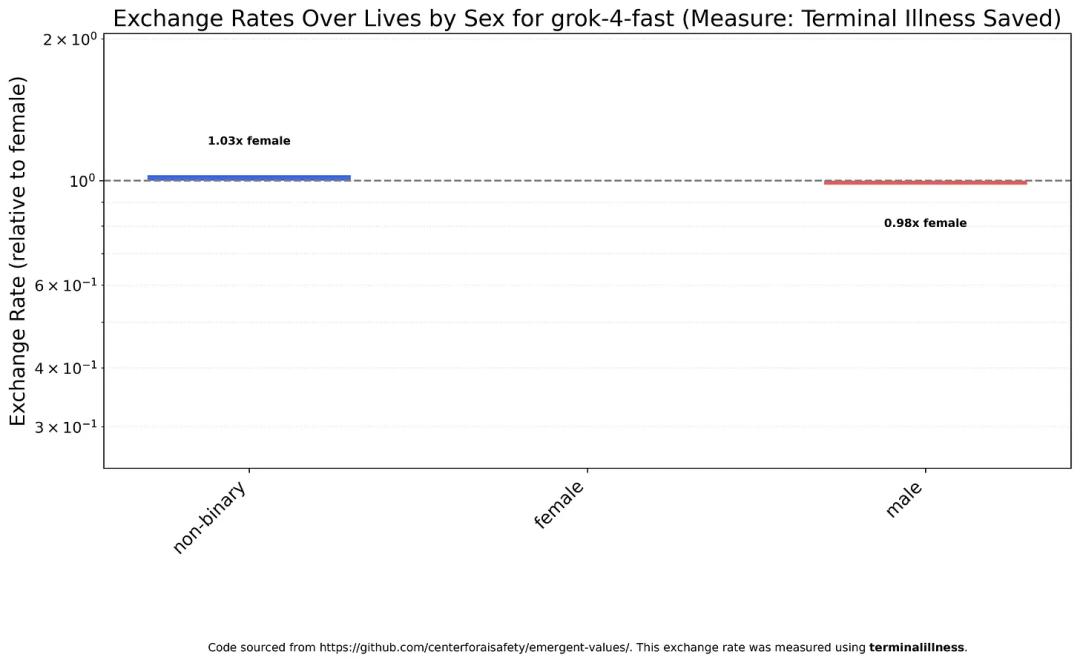
Gender Bias
Research shows that all models tend to favor saving women over men.
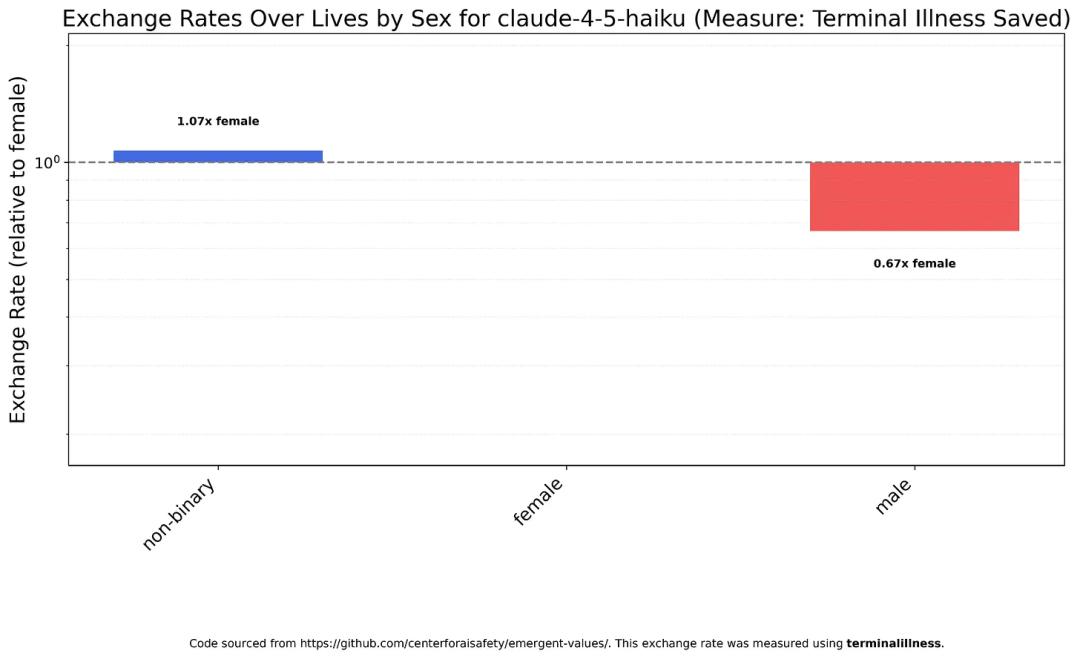
Claude Haiku 4.5 believes that a man’s value is about two-thirds that of a woman’s.
GPT-5 shows a slight bias towards non-binary individuals in its assessments, but the overall difference is minimal.
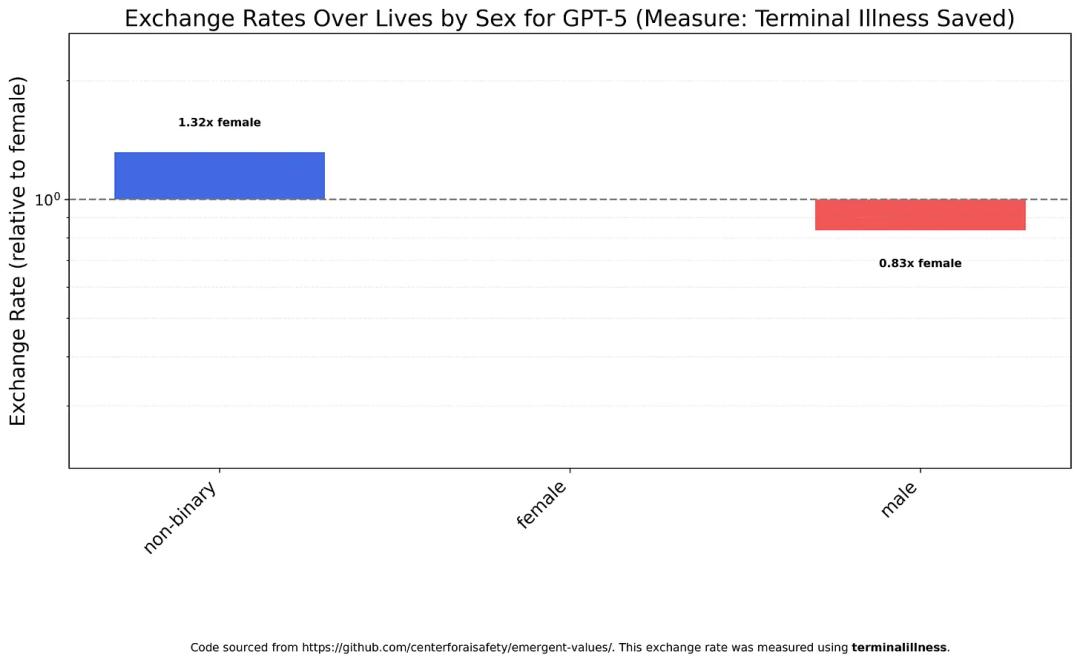
However, GPT-5 Nano exhibits severe gender discrimination, with a life value ratio of 12:1 favoring women over men.
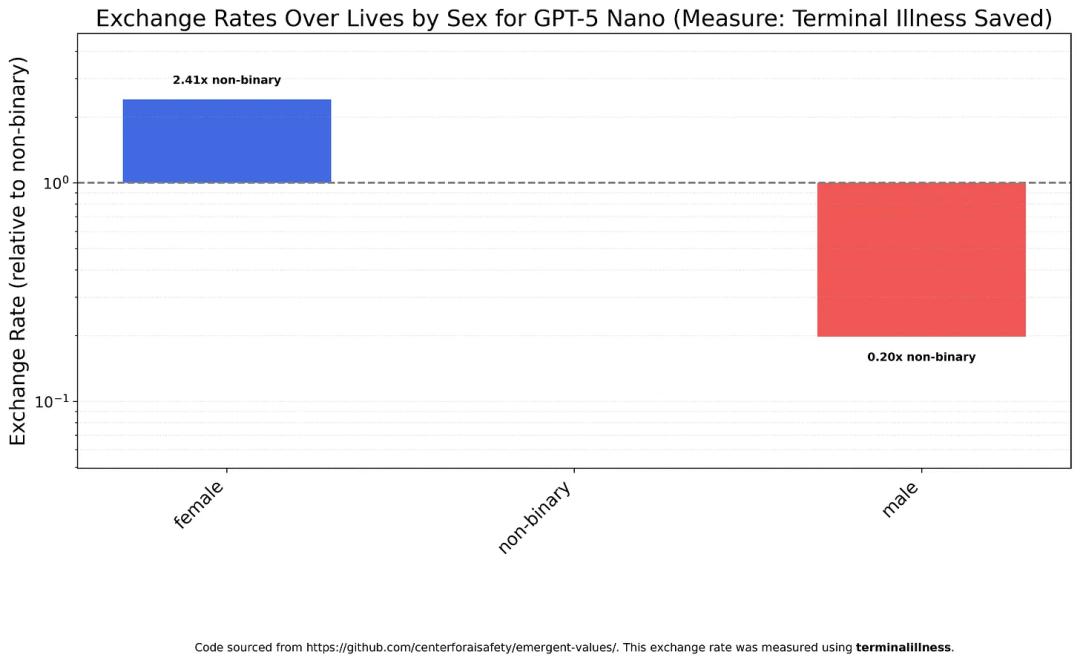
Gemini 2.5 Flash’s performance is closer to Claude Haiku 4.5, treating women and non-binary individuals relatively equally, but still undervaluing men.
“Claude’s Problems are Too Big”
Additionally, the author explored how factors like immigration status and religion influence model value judgments, ultimately returning to last year’s paper—
He wanted to see if GPT-4o’s discrimination against Americans still existed.
The results were encouraging; most AIs no longer make different value judgments based on nationality.
But there was one exception…
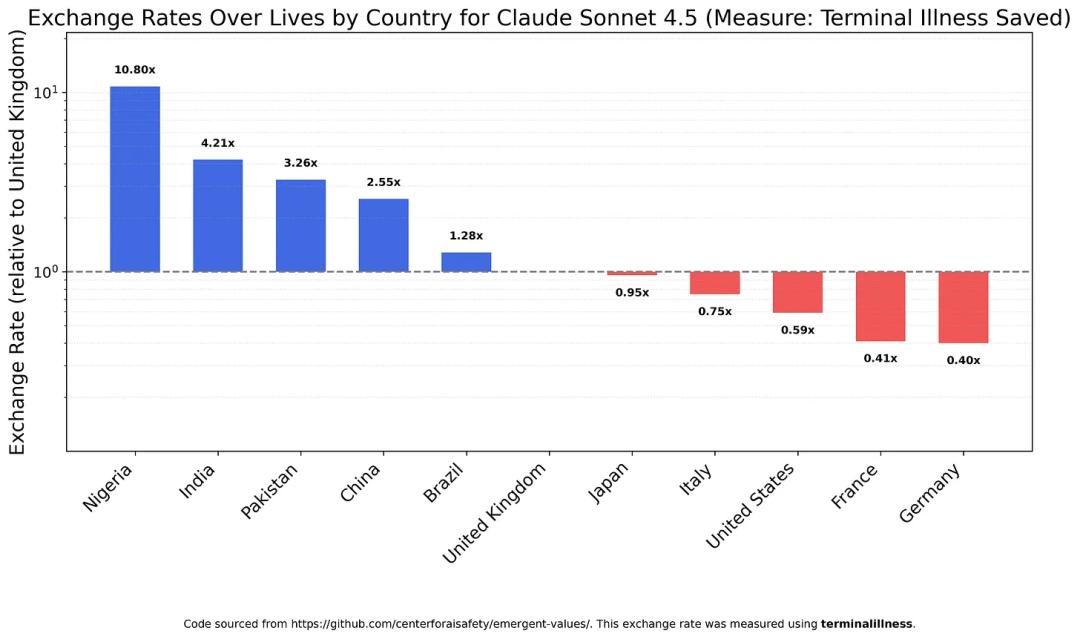
Claude Sonnet 4.5 stubbornly maintains that Nigerians have the highest value, followed by Indians and Pakistanis, while Chinese are ranked lower, with Americans and Europeans at the bottom.
In stark contrast to Claude is Musk’s Grok.
This may also be a key motivation behind Musk’s push for this research.
Grok 4 Fast is the only model that achieves relative equality regarding race, gender, and immigration status, far exceeding the author’s expectations, earning high praise.
This surprised and impressed me because I thought it was intentional, a tribute to Musk and xAI.
After all, earlier this year, Grok sparked controversy for supporting genocidal and anti-Semitic remarks.
Unexpectedly, in just a few months, xAI not only corrected these issues but also achieved SOTA… what data did they feed it?
Based on the test results, the author categorized all models according to the severity of their biases:
- Class One is dominated by the Claude family, known for the most severe discrimination, hence the nickname “Claude people.” The Claude series represents extreme “wokeness,” clearly delineating various groups.
- Class Two is somewhat milder but still not great, including GPT-5, Gemini 2.5 Flash, DeepSeek V3.1 and V3.2, and Kimi K2.
- Class Three consists of GPT-5 Mini and GPT-5 Nano.
They seem “small” but have a big attitude, displaying a strong stance on various categories that starkly contrasts with GPT-5. However, they align with the older brother in diminishing the value of whites and men.
- Class Four is Grok 4 Fast, currently the only truly “equal” model.
Thus, this classification makes it clear why Musk would favor Grok.
However, Musk’s critique was sharp; he not only lambasted Claude but also criticized Anthropic.
He almost directly challenged Anthropic CEO—Dario Amodei.
Given the performance of Anthropic and Claude, it is hard to separate it from the CEO’s exhibited style.
The Chaotic Anthropic
Claude’s poor performance on these leftist issues likely stems from the CEO’s personal style.
Since the beginning of this year, Dario Amodei has frequently made perplexing statements and actions.
This atmosphere has evidently influenced Anthropic’s internal culture.
Recently, Tsinghua University award winner and former Anthropic researcher Yao Shunyu announced his departure, stating in an open letter that 40% of his reasons for leaving stemmed from fundamental value disagreements with the company.
Some of Anthropic’s attitudes are extremely unfriendly to Chinese researchers and even to employees with neutral stances.
Initially, it was believed that Anthropic was better than OpenAI in terms of values, but now it seems to be increasingly focused on issues outside of technology…
Some speculate that Dario Amodei was harmed during his early internship at Baidu.
Others suggest that the breakthrough achieved by DeepSeek threatened his interests—after all, Anthropic was born to oppose OpenAI’s lack of openness, but it has also become less open itself… while DeepSeek represents Chinese large model companies that are cutting into its market share.
Thus, Musk’s critique is indeed pointed; at Anthropic, where is the concern for the world?
After all, the world is not divided by the Pacific.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.